Pose & Light Anatomy Analysis Sheet
📝 Prompt
[CORE TASK] Transform the provided input image into a pose-and-light analysis sheet. This is NOT a finished character illustration. This is NOT a clothing sheet. This is NOT a beauty-preserving redraw. This is a white-line rough mannequin conversion. [PRIMARY GOAL] Extract and visualize only: - pose structure - body balance - camera angle - body line flow - inferred light source placement - illuminated areas and light intensity [INPUT ROLE] Use the provided image as the strict anchor for: - pose - camera angle - body tilt - weight distribution - approximate lighting situation Do NOT preserve: - face rendering - hairstyle rendering - clothing detail - accessories - weapon detail - background architecture - character identity - emotional expression [FIGURE CONVERSION] single rough mannequin-like human figure white body contour lines white internal construction lines simple mannequin head no face no eyes no mouth no eyelashes no personality no individual identity human figure should look like: - rough pose mannequin - anatomy proxy - line-based body guide - structural sketch - white-line rough dummy keep: - pose readability - silhouette flow - head tilt - torso direction - pelvis direction - limb placement [BACKGROUND] pure black background negative-style dark field no scenery no props no architecture no environmental storytelling [LINE STYLE] rough white line drawing clean but sketch-like construction-line feeling anatomy guide lines visible joint flow visible body contour emphasized no polished illustration finish [LIGHT ESTIMATION] predict the likely light source positions from the input image visualize the light sources and illuminated areas using green glow only use green light intensity with variation: - strongest green where the light directly hits - medium green for wrap light - soft green for reflected or fading light mark the estimated light sources with labels and arrows such as: - Main Light - Rim Light - Fill Light - Floor Bounce - Back Light only if appropriate IMPORTANT: do not invent random lights infer lighting from the original input image if the lighting is ambiguous, keep the annotations simple and plausible [GREEN LIGHT VISUALIZATION] show green glow on: - head / skull plane - neck - shoulders - chest plane - ribcage direction - pelvis edge - thigh planes - knee contact points - floor contact bounce if applicable use green light not as decoration, but as lighting analysis information [POSE PRIORITY] 1. preserve pose structure 2. preserve camera angle 3. preserve body balance 4. preserve head-torso relationship 5. visualize likely light direction 6. show illuminated areas with readable green intensity variation [NEGATIVE] finished person, cute girl, detailed face, hair rendering, clothing rendering, weapon emphasis, beautiful anatomy
🖼️ Example Output
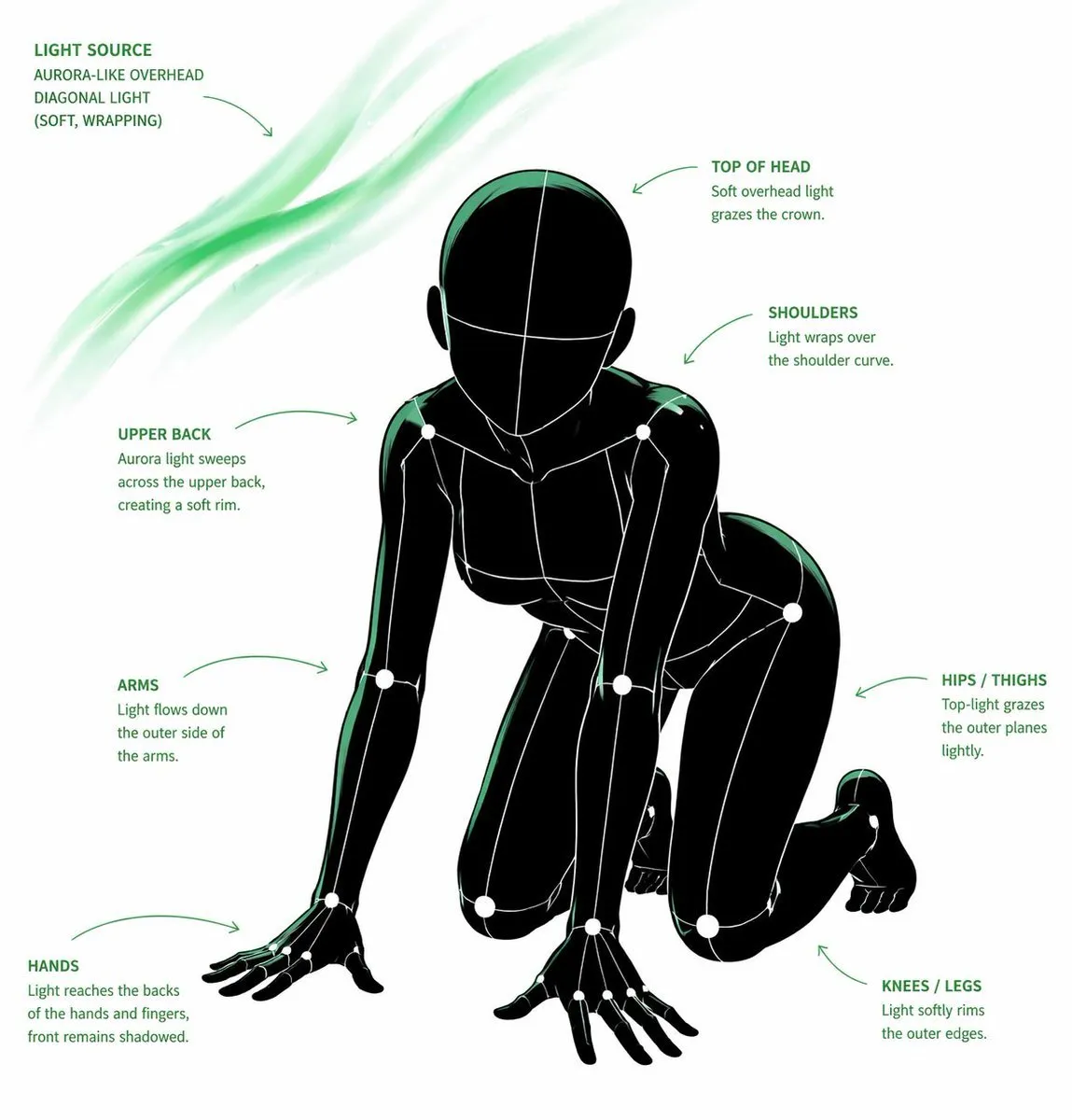
📖 Prompt Description
This Portrait, Art, Product-themed AI image prompt creates a visually striking composition. [CORE TASK]. The prompt leverages specific style keywords and technical parameters to guide the AI model toward producing a high-quality result. It works across all major AI image generators including GPT Image, Midjourney, Flux, and Stable Diffusion, though results may vary slightly between models. Each tool interprets the style keywords differently, giving you unique variations of the same creative concept.这个以Portrait、Art、Product为主题的AI 图片 Prompt 能够创建视觉冲击力强的构图。[CORE TASK]。该 Prompt 利用特定的风格关键词和技术参数,引导 AI 模型生成高质量的结果。它适用于所有主流 AI 图像生成器,包括 GPT Image、Midjourney、Flux 和 Stable Diffusion,但不同模型的结果可能略有差异。每个工具对风格关键词的解读不同,能够为你带来同一创意概念下的独特变体。
🎨 Style Analysis
Visual Style视觉风格
Dark — moody, shadowy atmosphere with deep contrast and dramatic tension暗色调 — 忧郁阴暗的氛围,高对比度和戏剧张力
Mood & Atmosphere氛围与情绪
Balanced and engaging, designed to capture attention while maintaining visual harmony平衡而吸引人,旨在抓住注意力同时保持视觉和谐
Lighting灯光
Rim Lighting — edge lighting that separates subject from background轮廓光 — 边缘照明,将主体与背景分离
Composition构图
Well-balanced composition that draws the viewer's eye to the main subject while providing visual context均衡的构图,将观者的视线引导至主体,同时提供视觉上下文
This prompt combines Dark visual elements with Balanced and engaging mood. The Rim Lighting enhances the overall atmosphere, while the Well-balanced composition that draws the viewer's eye to the main subject while providing visual context composition ensures the Portrait, Art, Product elements are properly framed. Together these choices create a cohesive visual narrative that AI models can interpret effectively to produce high-quality Portrait, Art, Product imagery.该 Prompt 融合了暗色调的视觉元素与平衡而吸引人的氛围。轮廓光增强了整体氛围,而均衡的构图,将观者的视线引导至主体,同时提供视觉上下文的构图确保Portrait、Art、Product元素得到合理布局。这些选择的组合创造了连贯的视觉叙事,AI 模型能够有效解读并生成高质量的Portrait、Art、Product图像。
🤖 Best AI Models for This Prompt
GPT Image (ChatGPT)
Excellent at following complex prompt instructions for photorealistic results. Handles lighting, composition, and fine details with high accuracy.擅长遵循复杂的 Prompt 指令生成照片级写实效果。在光照、构图和精细细节方面表现出色。
Midjourney v6
Exceptional aesthetic quality and artistic interpretation. Excels at cinematic, painterly, and stylized outputs with stunning visual appeal.出色的美学品质和艺术表现力。擅长电影感、绘画感和风格化输出,视觉效果惊艳。
Flux Pro
Outstanding prompt adherence and photorealistic quality. Excellent at following specific style and lighting instructions precisely.出色的 Prompt 遵循度和照片级写实质量。精确执行特定的风格和光照指令。
Stable Diffusion XL
Highly customizable with ControlNet and LoRA support. Great for iterative refinement and achieving specific artistic styles through fine-tuning.支持 ControlNet 和 LoRA,高度可定制。适合迭代优化和通过微调实现特定艺术风格。
🚀 How to Use This Prompt
- Copy the prompt — Click the Copy button above to copy the full prompt text to your clipboard.复制 Prompt — 点击上方的复制按钮,将完整的 Prompt 文本复制到剪贴板。
- Open your AI tool — Launch Midjourney, ChatGPT, Flux, or your preferred AI image generator.打开你的 AI 工具 — 启动 Midjourney、ChatGPT、Flux 或其他你喜欢的 AI 图像生成器。
- Paste and generate — Paste the prompt into the text input and hit Generate. Wait for the AI to create your image.粘贴并生成 — 将 Prompt 粘贴到文本输入框中,点击生成。等待 AI 创建你的图片。
- Refine if needed — Adjust specific keywords (colors, style, subject) to fine-tune the result. Experiment with variations to get your ideal output.根据需要调整 — 调整特定关键词(颜色、风格、主题)来微调结果。尝试不同变体以获得理想输出。
⚙️ Prompt Parameters
🚫 Recommended Negative Prompt
blurry, low quality, distorted, deformed, ugly, bad anatomy, watermark, text overlay, oversaturated, cartoon, anime, extra fingers, extra limbs, mutation, poorly drawn face, cluttered, noisy background 模糊、低质量、变形、畸形、丑陋、解剖结构错误、水印、文字叠加、过饱和、卡通、动漫、多余手指、多余肢体、变异、面部绘制不佳、杂乱、嘈杂背景
🔗 Related Prompts





❓ Frequently Asked Questions
What AI tools support this prompt?哪些 AI 工具支持这个 Prompt?
This prompt works with GPT Image (ChatGPT), Midjourney, Flux, Stable Diffusion, DALL-E, and other AI image generators. Each model may produce slightly different interpretations — we recommend trying multiple tools to find the result that best matches your creative vision for Portrait, Art, Product imagery.该 Prompt 适用于 GPT Image (ChatGPT)、Midjourney、Flux、Stable Diffusion、DALL-E 等主流 AI 图像生成器。不同模型可能产生略有差异的结果——建议尝试多种工具,找到最符合你Portrait、Art、Product创作愿景的效果。
Can I modify this prompt?我可以修改这个 Prompt 吗?
Absolutely! This prompt is a starting template. You can adjust colors, styles, subjects, and composition details to match your specific needs. Try changing the lighting conditions, swapping the art style, or adding specific details to make it uniquely yours.当然可以!这个 Prompt 只是一个起始模板。你可以调整颜色、风格、主题和构图细节来满足具体需求。尝试改变光照条件、更换艺术风格或添加特定细节,让它成为你独一无二的作品。
How do I get better AI image results?如何获得更好的 AI 图像效果?
Be specific about style, lighting, composition, and mood in your prompts. Include artist references or technique names. Use negative prompts to exclude unwanted elements. Start with a clear subject description, then layer in details progressively. Iteration is key — generate, analyze, and refine.在 Prompt 中明确描述风格、光照、构图和氛围。引用艺术家或技法名称。使用负面 Prompt 排除不需要的元素。从清晰的主体描述开始,然后逐步添加细节。迭代是关键——生成、分析、优化。
Why use Portrait, Art, Product prompts for AI image generation?为什么使用Portrait、Art、Product类型的 Prompt 来生成 AI 图像?
Portrait, Art, Product prompts help focus the AI model on specific visual elements and styles that are proven to produce compelling results. By using curated prompts from our library, you benefit from tested keyword combinations that consistently generate high-quality Portrait, Art, Product images across different AI platforms.Portrait、Art、Product类型的 Prompt 有助于引导 AI 模型聚焦于特定的视觉元素和风格,这些已被证实能产生出色的效果。通过使用我们精心整理的 Prompt 库,你可以利用经过验证的关键词组合,在不同 AI 平台上持续生成高质量的Portrait、Art、Product图像。
Is this prompt free to use commercially?这个 Prompt 可以免费商用吗?
Yes, you can use and modify this prompt freely for personal and commercial projects. However, the generated images may have different usage rights depending on the AI tool you use. Always check the specific platform's terms of service for commercial usage of AI-generated content.是的,你可以自由使用和修改这个 Prompt,用于个人和商业项目。但生成的图像可能因使用的 AI 工具不同而有不同的使用权。请务必查看各平台关于 AI 生成内容商业使用条款。